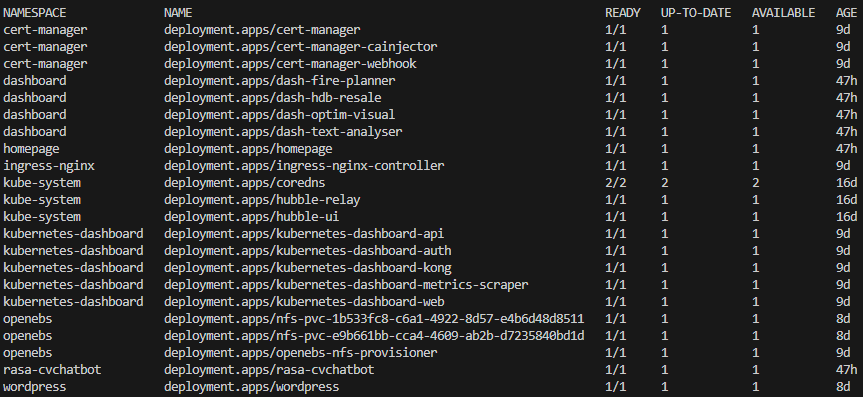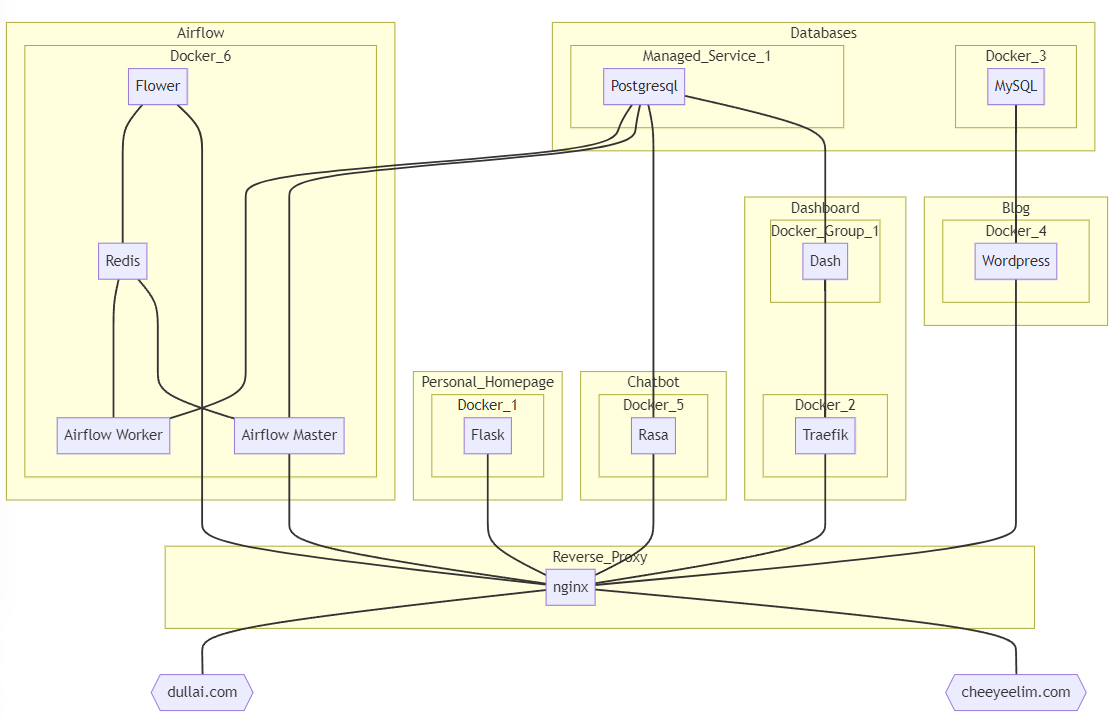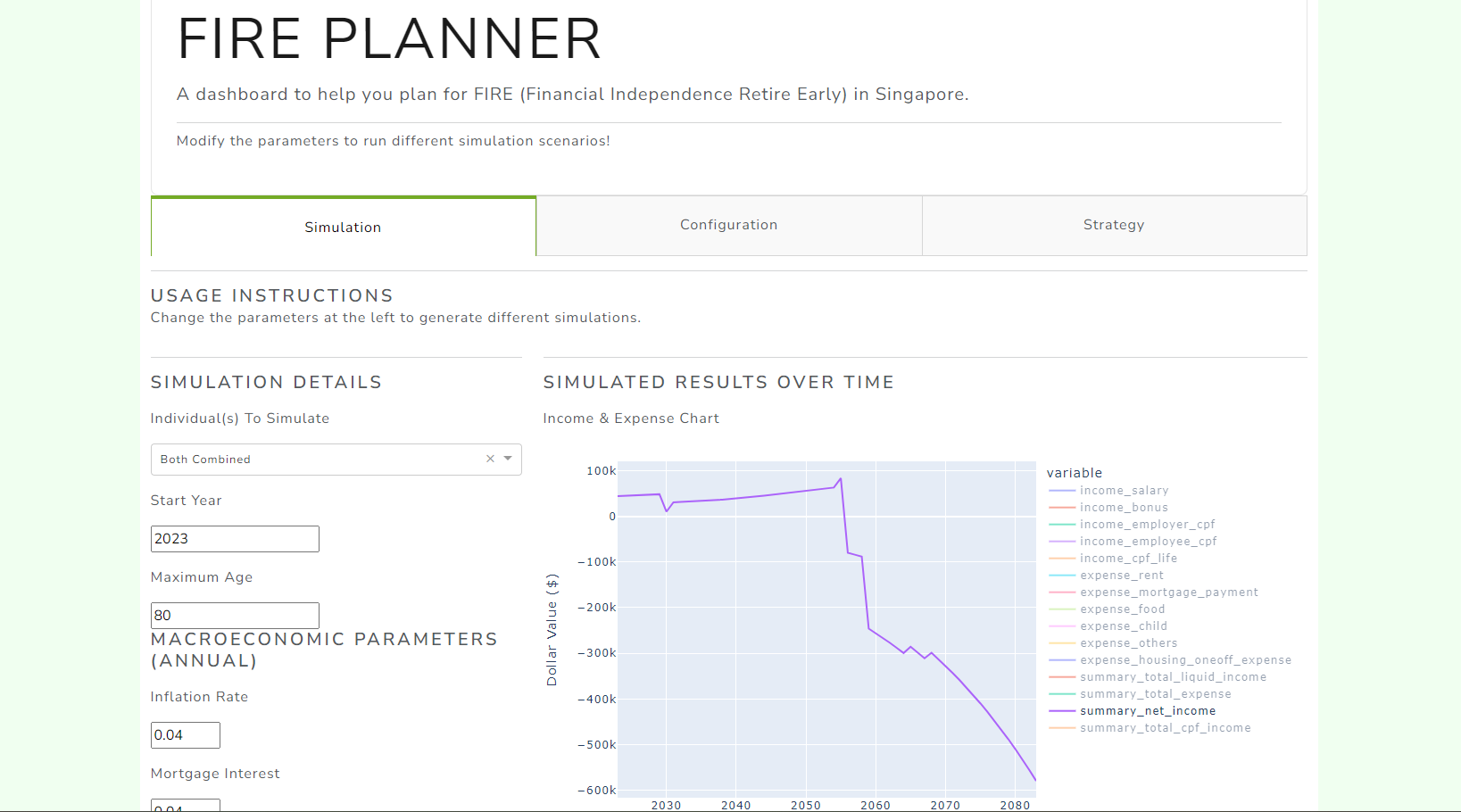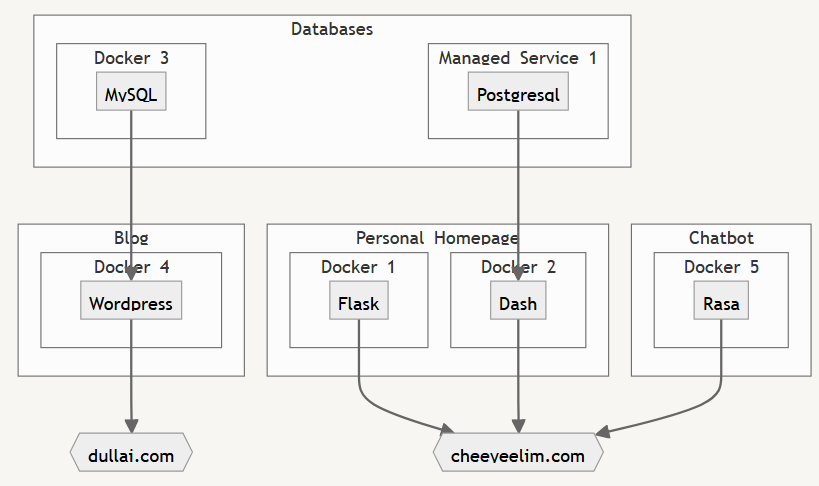
Time really does fly. It is now almost the end of 2024.
To close off 2024, I will be writing a post on a different topic each every week until the new year arrives.
My first post is about GitHub Copilot.
I’m rather late to the game in terms of adopting GitHub Copilot for my personal projects.
But it has really blown me out of the water so far.
Copilot helped me navigated the complex territory of Kubernetes/Helm YAML manifests, but was less helpful when I’m working with polars.
Some quick pros and cons are listed below.
Pros:
➕ Amazing context search ability based on currently opened files.
When asked a question, it will automatically search for relevant parts in opened files in VS Code to help produce a more relevant answer. This means it can suggest functions/methods from libraries that you are using and variable/column names that follow your convention.
➕ Great at explaining hard-to-search technical terms (e.g. special characters in Bash, regex).
In the olden days without LLM, it is really hard to search for special characters on Google especially if you do not know what they are called in English. But Copilot has no problem breaking down a string of special characters and explaining them one by one. In fact, Copilot taught me about heredoc in Bash.
Cons:
➖ Not useful on newer or rapidly changing libraries (e.g. polars).
Copilot does suggest wrong syntax from time to time, but it suffers the most when asked to work with newer or rapidly changing libraries. With polars, it kept on suggesting older APIs, e.g. with_column and groupby, instead of with_columns and group_by.
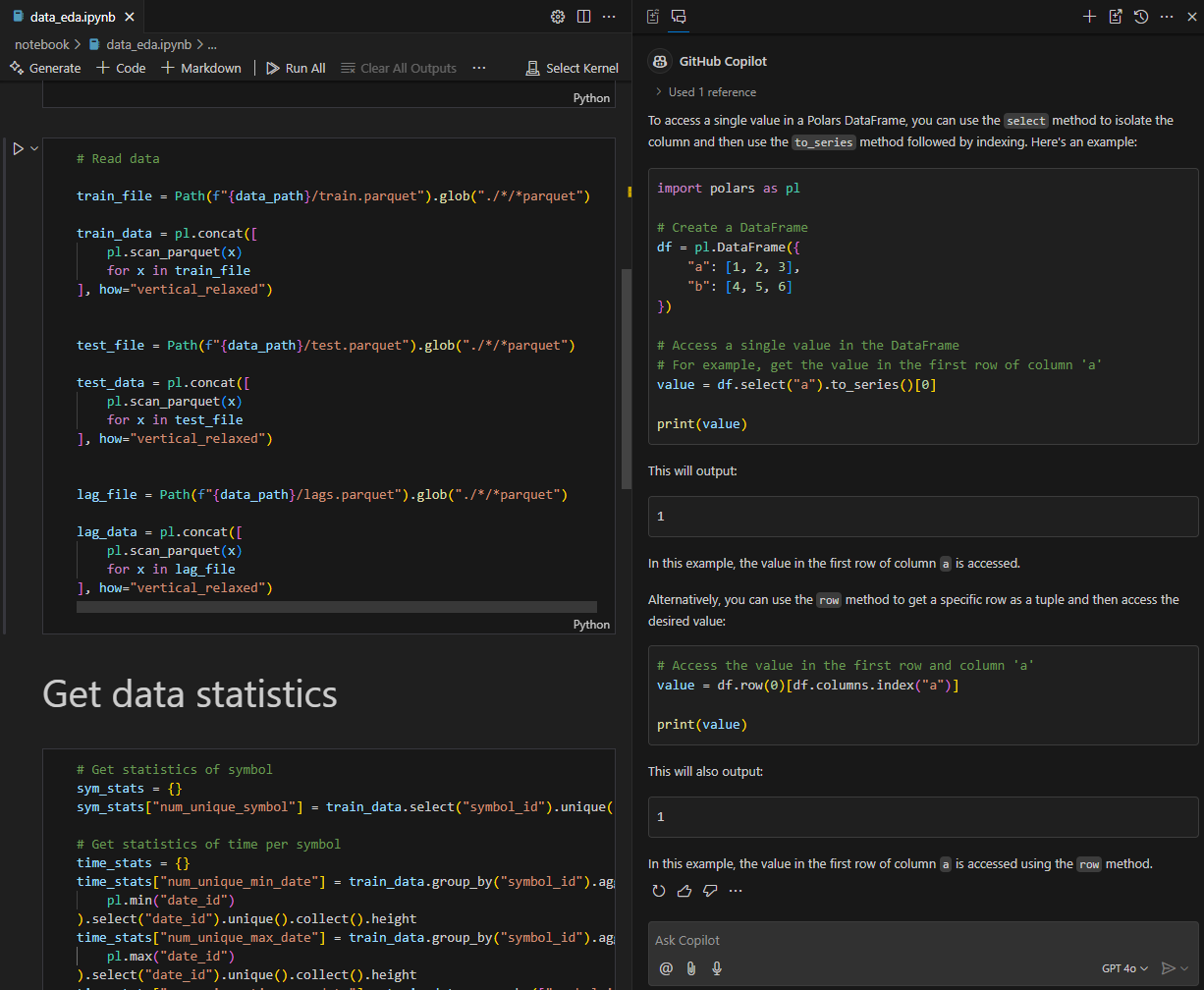
➖ Can suggest convoluted solutions when simpler ones exist.
To illustrate this using a recent example that I remembered. When asked on how can I access a value in a polars DataFrame, it suggested selecting a column, converting it into a series before accessing the value via index. Although in reality, the value can be accessed directly with square brackets or item().