I decided to set up my own website at the end of 2020.
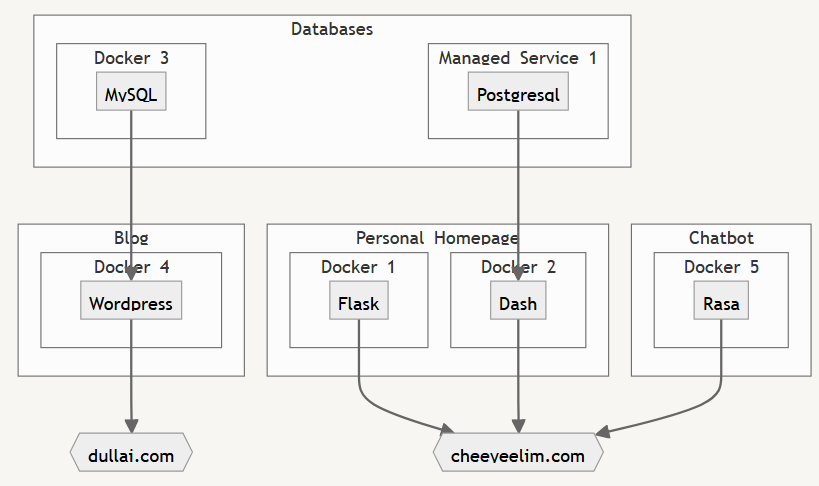
3 years later, I run 2 websites backed by multiple supporting services (see image below), all set up and operated by myself.
My goals are (1) to set up a robust infrastructure that can ensure my websites/services are always up, and (2) to set up a development framework that minimises maintenance efforts.
For the infrastructure, each service is dockerised with custom images and deployed on my favourite cloud service provider (DigitalOcean).
Uptime monitor (UptimeRobot) and web analytics service (Google Analytics) have been set up to constantly check the status of the services.
As for the development framework, I develop locally on VS Code with Windows Subsystem for Linux (WSL), with enforced linting and formatting via pre-commit hooks.
Codes are pushed to repos on GitHub, while images are pushed to the container registry on Docker Hub.
I paid special attention to code quality, especially on Python codes, to make maintenance easier. But overall code quality is not as high as I would like it to be, because I need to work with multiple languages (i.e. Python, Bash, Javascript, PHP, HTML/CSS, SQL) on this stack and I am less familiar with some of these languages.
So far I am quite on track with my goals, with (1) these services achieving 99.5% SLA yearly over the past 3 years and (2) each service taking about 3-4 hours of maintenance time per year. Granted, I am not operating high-volume or complex websites, but still achieving these requires some discipline.
I realise there are some parts that are still missing from this stack/setup, for example, full CI/CD integration, Kubernetes for service deployment, and MLOps services.
But perhaps I should stop tinkering with the infrastructure, and start working on more content creations?